Reverse入门参考
免责声明:re菜鸡,纯用于带大一入门写此文章,还需不断进步
前言
主要分为9个模块
1.汇编与IDA使用
2.静态分析
3.动态调试(本地+远程)
4.迷宫maze逆向
5.壳与混淆
6.各类算法逆向
7.花指令基础
8.SMC基础
9.Python逆向基础
汇编与ida使用
ida使用参考鄙人之前写过的
汇编知识点
基础就是对寄存器和汇编码操作指令的了解,实际最主要还是根据main函数入口定位,五六百行汇编码人肉分析是基本功,鄙人基础不扎实,望学弟学妹能做到
快速入门版
核心概念
本质: 机器指令的助记符(MOV, ADD 等),是机器码的“人类可读”形式。直接对应CPU硬件操作。
核心任务: 操作 寄存器(Registers) 和 内存(Memory) 中的数据。
指令结构: 操作码 [操作数1] [, 操作数2] (如 MOV AX, 5)
低级性: 无高级语言的变量、类型系统(需手动管理内存)、复杂控制结构(需跳转实现)。
平台依赖: 汇编指令集和寄存器结构完全依赖于特定的CPU架构(如 x86, ARM, MIPS)。关键硬件组件(程序员视角)
寄存器 (Registers): CPU内部超高速存储单元。
通用寄存器 (GPRs): 存放数据和地址(如 x86: AX, BX, CX, DX, EAX, RAX; ARM: R0-R12)。
指令指针 (IP / PC): 指向下一条要执行的指令地址(x86: EIP/RIP; ARM: R15(PC))。
堆栈指针 (SP): 指向当前栈顶(x86: ESP/RSP; ARM: R13(SP))。
标志寄存器 (Flags): 存储上一条指令执行结果的状态(如 ZF 零标志, CF 进位标志, SF 符号标志)。控制条件跳转 (JZ, JC 等)。
内存 (Memory): RAM,按字节编址。寄存器操作速度远快于内存。
总线 (Bus): CPU、内存、外设间传输数据的通道。基本指令类型
数据传输:
MOV dest, src: 复制数据(寄存器<->寄存器, 寄存器<->内存, 立即数->寄存器/内存)。内存间不能直接MOV!
算术运算:
ADD dest, src: 加法(影响标志位)
SUB dest, src: 减法(影响标志位)
INC dest: 加1
DEC dest: 减1
MUL / IMUL: 无/有符号乘法
DIV / IDIV: 无/有符号除法
逻辑运算:
AND dest, src: 按位与
OR dest, src: 按位或
XOR dest, src: 按位异或(常用清零寄存器 XOR AX, AX)
NOT dest: 按位取反
SHL / SHR / SAL / SAR: 逻辑/算术左移/右移
控制流:
JMP label: 无条件跳转到标签处。
条件跳转: 根据标志寄存器跳转(JE/JZ 等于/零, JNE/JNZ 不等于/非零, JG/JNLE 大于, JL/JNGE 小于, JC 进位, JNC 无进位 等)。
CALL func_label: 调用子程序(将下一条指令地址压栈,并跳转)。
RET: 从子程序返回(从栈顶弹出地址并跳回)。
堆栈操作:
PUSH src: 将数据压入栈顶(SP减小)。
POP dest: 从栈顶弹出数据到目标(SP增大)。遵循 LIFO (后进先出) 原则。
用途: 函数调用参数传递/局部变量存储、保存寄存器状态、中断处理。寻址方式 (如何指定操作数位置)
立即寻址: 操作数是指令本身的一部分(常数),如 MOV AX, 42
寄存器寻址: 操作数在寄存器中,如 ADD BX, CX
直接寻址: 操作数在内存中,地址直接给出,如 MOV AX, [0x1234] (早期/特定场景)
寄存器间接寻址: 操作数地址在寄存器中,如 MOV AL, [BX] (x86), LDR R0, [R1] (ARM)
寄存器相对寻址: 地址 = 寄存器内容 + 偏移量,如 MOV AX, [SI + 10] (x86), LDR R0, [R1, #4] (ARM) - 访问数组/结构体成员常用
基址变址寻址: 地址 = 基址寄存器 + 变址寄存器,如 MOV AX, [BX + SI] (x86)
基址变址相对寻址: 地址 = 基址寄存器 + 变址寄存器 + 偏移量,如 MOV AX, [BX + SI + 8] (x86) - 访问二维数组常用
静态分析与动态调试
f5看代码加交叉引用分析以及linux下的远程动调,网上参考很多,不过多赘述
迷宫题型
算是对大一数据结构BFS和DFS的复习重温,用相应代码跑一遍路径即可,深度和广度对答案的影响考虑过,一般没太大问题,之前开放实验也给大家出过相应题目
eg
1 | |
对应代码
1 | |
壳与混淆
ctf比赛中常用upx壳,安卓题目脱壳目前鄙人还未做到,混淆难的不用看,对于新师傅来说不太友好,关注简单的函数名变量名混淆,简单汇编代码混淆即可
壳的概念
“壳”,顾名思义,是程序外面的 “保护层”,主要分为压缩壳和加密壳两种。比赛中常见的一般是压缩壳,它在程序中加入一些代码隐藏程序真正的入口,使其难以被反编译。
进一步讲
壳实质上是⼀个⼦程序,在程序运⾏时⾸先取得控制权并对程序进⾏压缩,同时隐藏程序真正的OEP。 脱壳的⽬的就是找到真正的OEP。
OEP:程序的⼊⼝点,软件加壳就是隐藏了OEP(或者⽤了假的OEP), 只要我们找到程序真正的 OEP,就可以脱壳。
PUSHAD (所有寄存器压栈) 代表程序的⼊⼝点,POPAD (出栈) 代表程序的 出⼝点。
DLL(Dynamic Link Library)⽂件为动态链接库⽂件,很多Windows可执⾏⽂件并不是⼀个可以完整执⾏ 的⽂件,⽽是被分割成了多个DLL⽂件。当我们执⾏⼀个⽂件的时候,对应的DLL⽂件就会被调⽤。
ITA(Import Address Table):导⼊地址表。在不同版本的Windows系统中DLL的版本不同,那么我们需要借助ITA,获取函数的真实地址。
查壳
软件:EXEInfoPE、PEID、StudyPE+、DIE 等
它们的使用都差不多,下面以 DIE 为例: 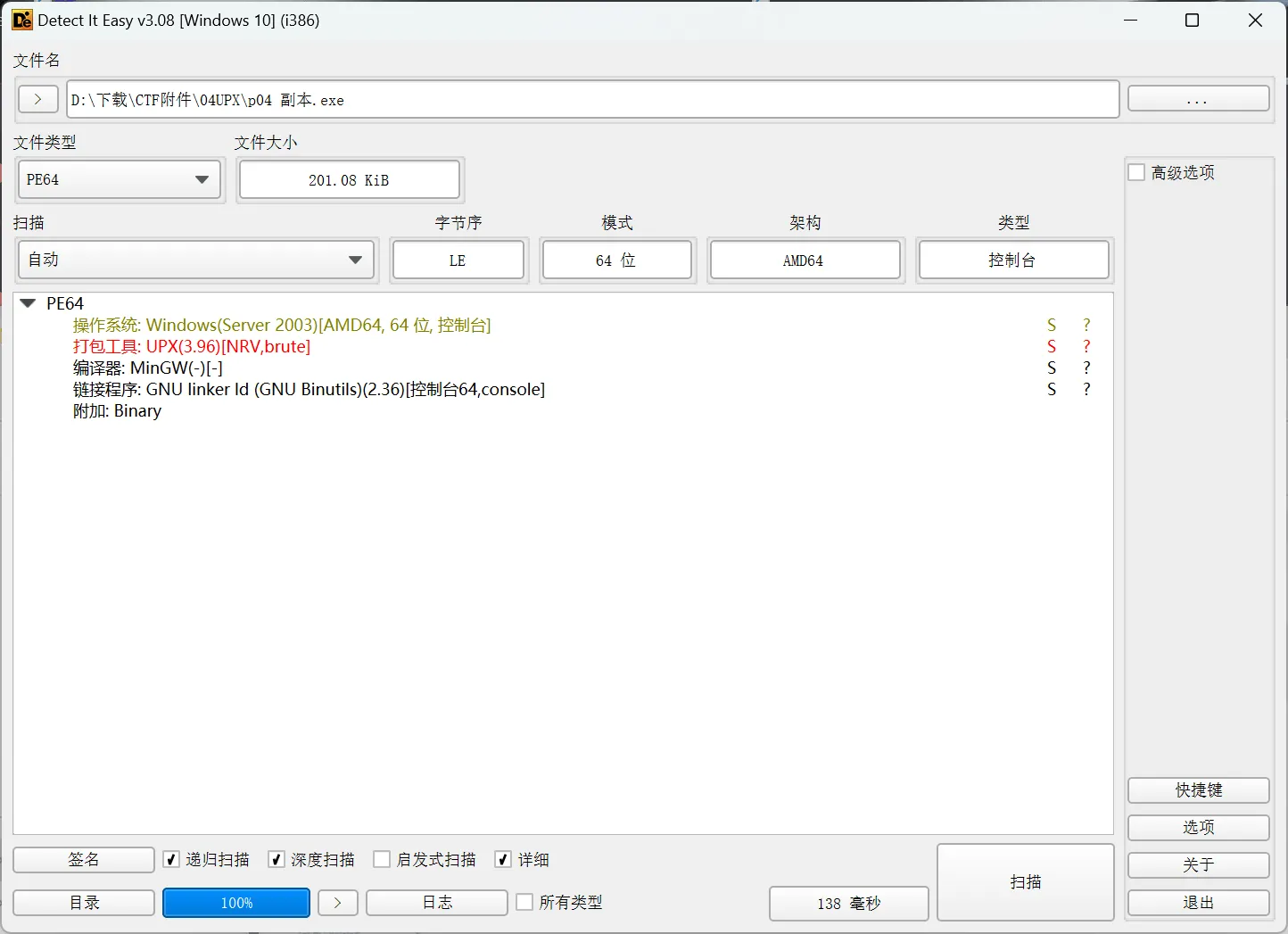
exeinfope eg:
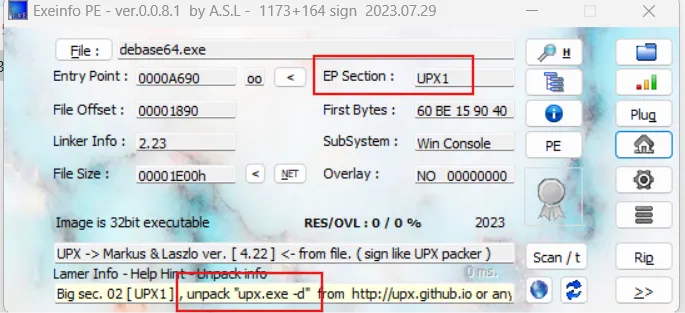
我们可以看到程序使用的操作系统位数、加壳的情况等等。
如果对应EP Section被修改,需要使用二进制编辑工具修改相关内容,UPX需为大写且共有三处
脱壳
工具脱
使用官方工具 upx.exe ,使用命令即为 upx.exe -d <文件(加后缀)>
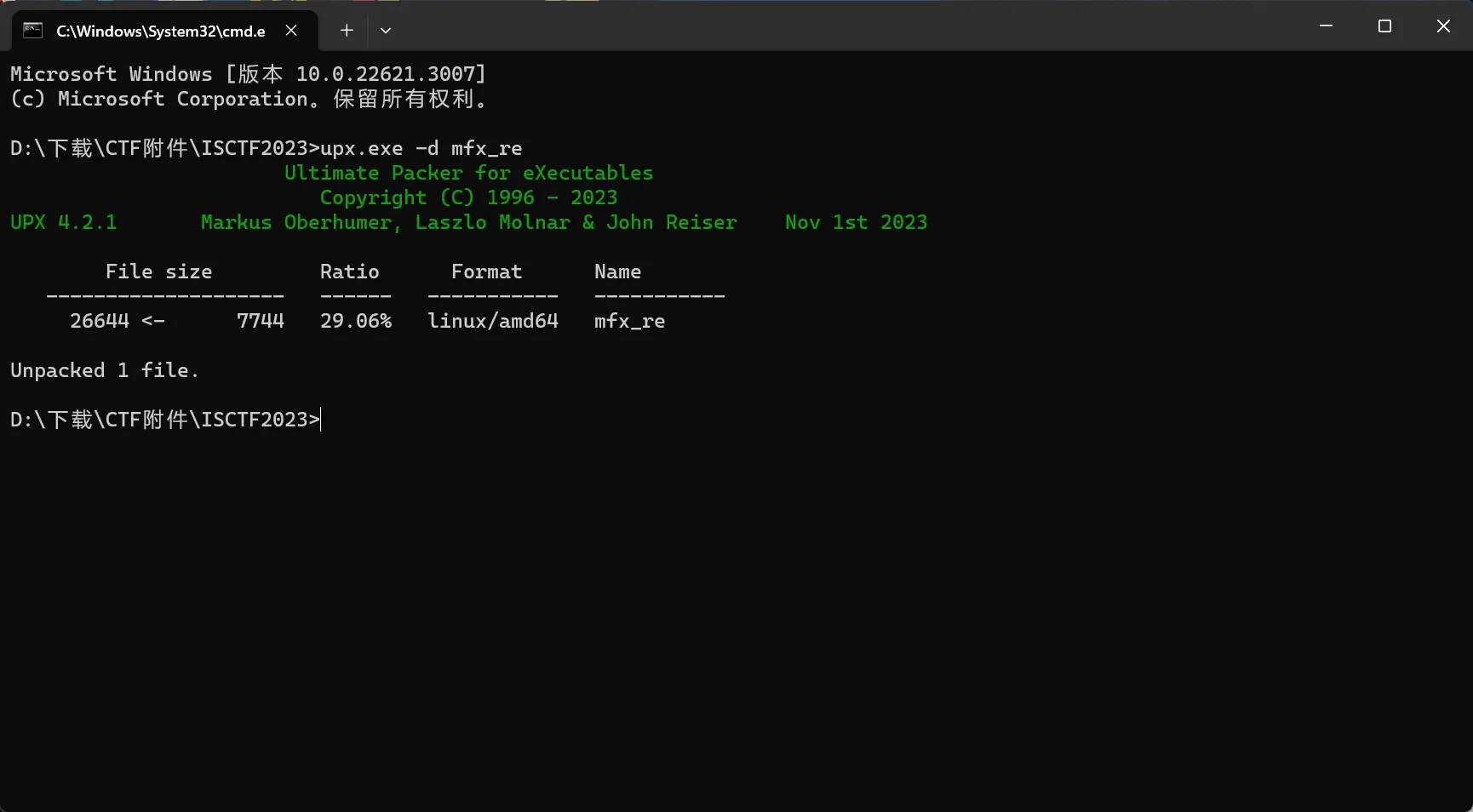
手脱UPX壳–x64dbg为例
这块参考博客具体文章,鄙人懒得再搬了
算法逆向
新手入门就常见两个base64和rc4,rsa等加密算法其余学长会给予介绍
base64
严格来讲,base系列不能说是加密,更像是一种编码方式,用于传输协议仅支持ascii字符的情况
原理:
首先将输入数据分割成每三个字节(共 24 位)一组,接着将这 24 位分割为四个 6 位的块(因为 Base64 中每个字符代表 6 位二进制数据)。最后,通过查找表将这些 6 位块映射为相应的 Base64 字符。若输入数据的字节数非 3 的倍数,则在数据末尾添加=字符作为填充,以确保编码结果的长度符合 Base64 规范。
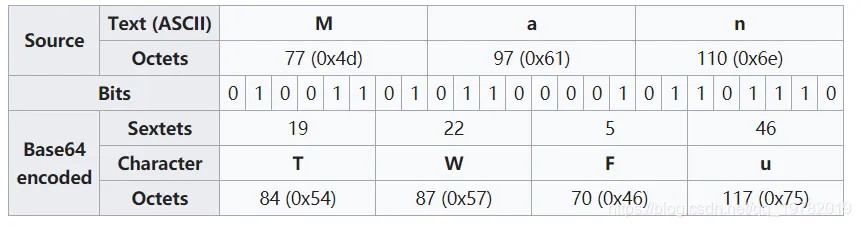
涉及字符:A-Za-z0-9+/= (这也是标准base64表)
补位:
网上介绍算法的有很多,但是补位不太详细,参考这篇文章https://xie.infoq.cn/article/d4ea16f136f588f41e9d8b73f
如果字节数不是 3 的倍数,那么余数可能是 1 或 2,所以补位也需要分两种情况。
余数为 1,二进制末尾补 4 个 0,最后多出来的这个字符会编码成 2 个 base64 字符,最后再补两个=,比如宋的拼音 song,余数为 1
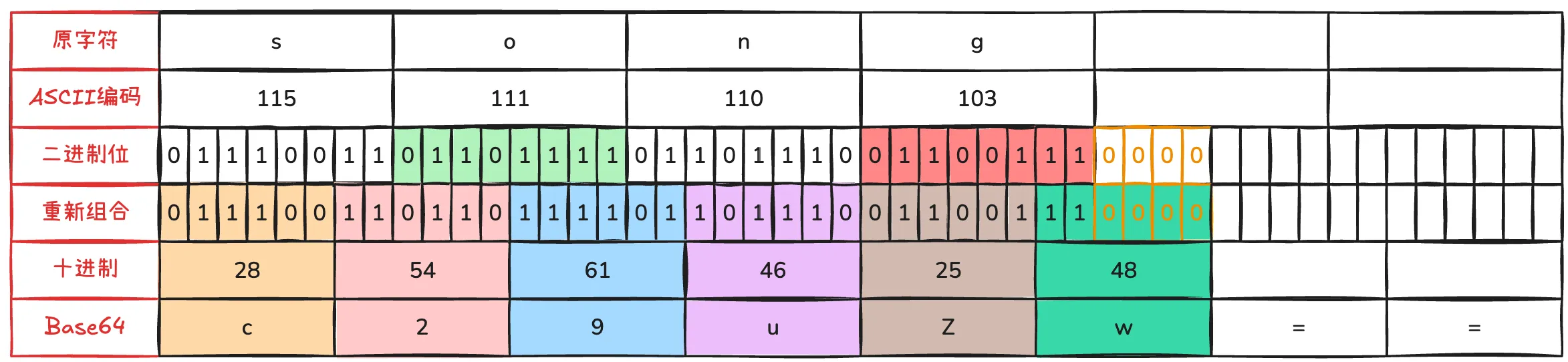
在这基础上最后还得补上 2 个 =,最终 song 编码为 c29uZw==
余数为 2,二进制末尾补 2 个 0,编码后末尾再补 1 个 =,比如 ab,余数为 2
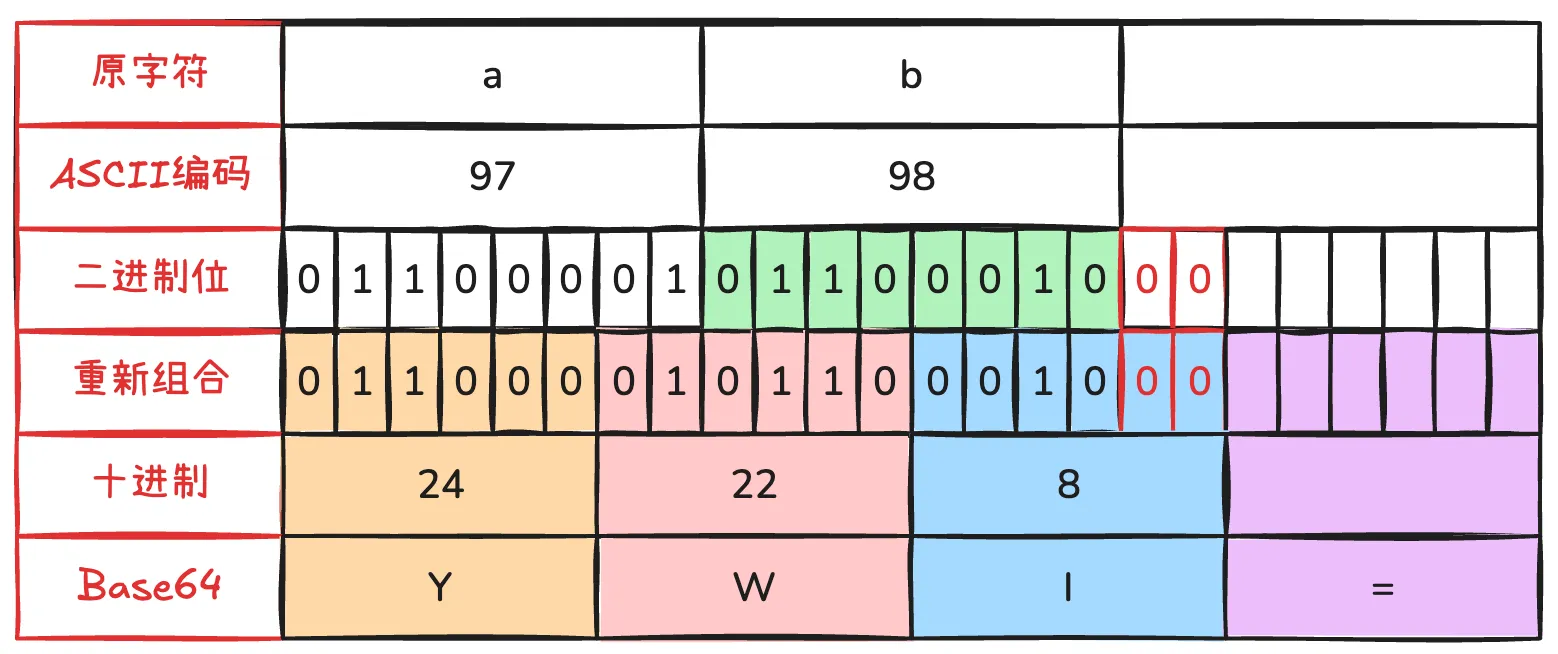
最终 ab 编码为 YWI=
加解密实现:
工具:网上有很多加解密base的在线网站,首推cyberchef,misc学长有介绍过
手搓:
1 | |
代码理解为主,现在很多解密基本都是调用相关库函数解密,涉及密文密钥之类的格式处理,不外显具体加解密过程,前面的算法介绍有点简陋,这里结合ai注释理解更方便一点
rc4
rc4算是序列密码里的经典了,序列密码主要重心放在密钥流生成,加解密其实就是一个xor,很多时候没有魔改的话直接动态调试一遍输入密文就能得到明文,参考下图
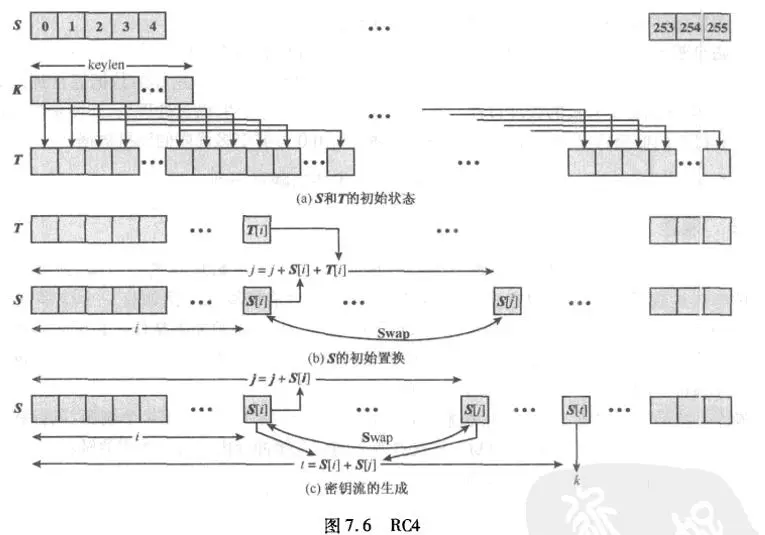
结合代码看应该更清楚
1 | |
1. 初始化阶段
1 | |
- 创建S盒:初始化一个长度为256的数组 S,值从0到255( [ 0, 1, 2, …, 255 ] )
2. 密钥调度算法(KSA)
1 | |
- 密钥混合:
- 遍历 i 从0到255。
- 计算索引 j :
j = (当前j + S[i] + 密钥字节) % 256
其中 密钥字节 = key[i % len(key)](循环使用密钥)。 - 交换 S[i]和S[j]:打乱S盒的初始顺序。
- 目的:将密钥的随机性扩散到整个S盒中。
示例:密钥”Secret”(十六进制53 65 63 72 65 74)
当i=0时:j = (0 + S[0] + key[0]) % 256 = (0 + 0 + 0x53) % 256 = 83,交换S[0]和S[83]。
3. 伪随机生成算法(PRGA)与加密
1 | |
生成密钥流字节:
a. 更新索引i = (i + 1) % 256。 b. 更新索引j = (j + S[i]) % 256。 c. 交换S[i]和S[j](动态修改S盒)。 d. 计算密钥字节k = S[(S[i] + S[j]) % 256]。加密/解密:
将明文/密文字节char与密钥流字节k进行异或操作(char ^ k)。
后继
剩余的花指令,python pyc逆向等视反馈选择性讲解,理解为主,学弟学妹们加油,自己的博客可以搭起来了,输出反馈模式倒转强化正向输入是一件挺有成就感的事情。个人感觉还是web简单一点,re入门之后跨度很大,各个方向都差不多,学长当时也很迷茫,逆向这行需要十年磨一剑的觉悟和静下心来阅读代码的沉稳和自信,开发和逆向就像是对立面,当你成为逆向大佬,离开发佬注意的日子也就不远了,加油吧。。。。。